Die deskriptive Statistik steht Ihnen für eingeladene Geofaktoren, Höhenraster, Voxelmodelle und Parameter (Parameter Manager/LocViewObject) zur Verfügung. Bei irregulären Voxelmodellen und bei Parametern können auch Datenreihen mit Text analysiert werden.
¶ Deskriptive Statsitik für numerische Daten
Sie können sich zur angewählten Datenreihe (meist erreichbar über das Rechtsklick-Kontextmenü der Objekte ode im ParameterManager) jeweils ein Histogramm, den Boxplot, eine kumulative "Kurve" (0-1, normed cumulative frequency) oder den QQ-Plot anschauen.
Die deskriptive Statistik von numerischen Daten aus Rasterdaten, wie Geofaktoren und Höhenraster, kann auf Daten innerhalb eines ausgewählten Polygon-Shapes beschränkt werden. Das kann auch auf einem gefilterten Shape erfolgen. Wie Sie Shape-Polygone filtern erfahren Sie im verlinkten Artikel. Setzen Sie einfach ein Häkchen bei Only for chosen Polygon und wählen aus der Dropdown-Liste das eingeladene Shape aus. Sofort aktualisiert sich die Ansicht.
Unter der Grafik sehen Sie auch ein kleines Textfeld. Es zeigt die Koordinaten Ihrer Mausposition im Grafik-Feld. Es soll Ihnen bei der Auswertung der Graphen helfen.
Mit dem Knopf Export statistics speichern Sie den Text zur statistischen Asuwertung in einen einfachen Text-File.
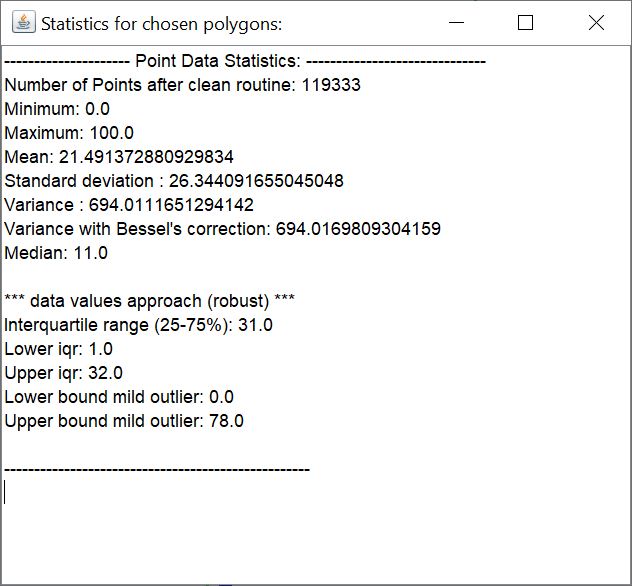 Mit dem Knopf *Statistics* öffnen Sie ein kleines Textfeld mit der statistischen Asuwertung in einen einfachen Text.
Mit dem Knopf *Statistics* öffnen Sie ein kleines Textfeld mit der statistischen Asuwertung in einen einfachen Text.
¶ Histogram
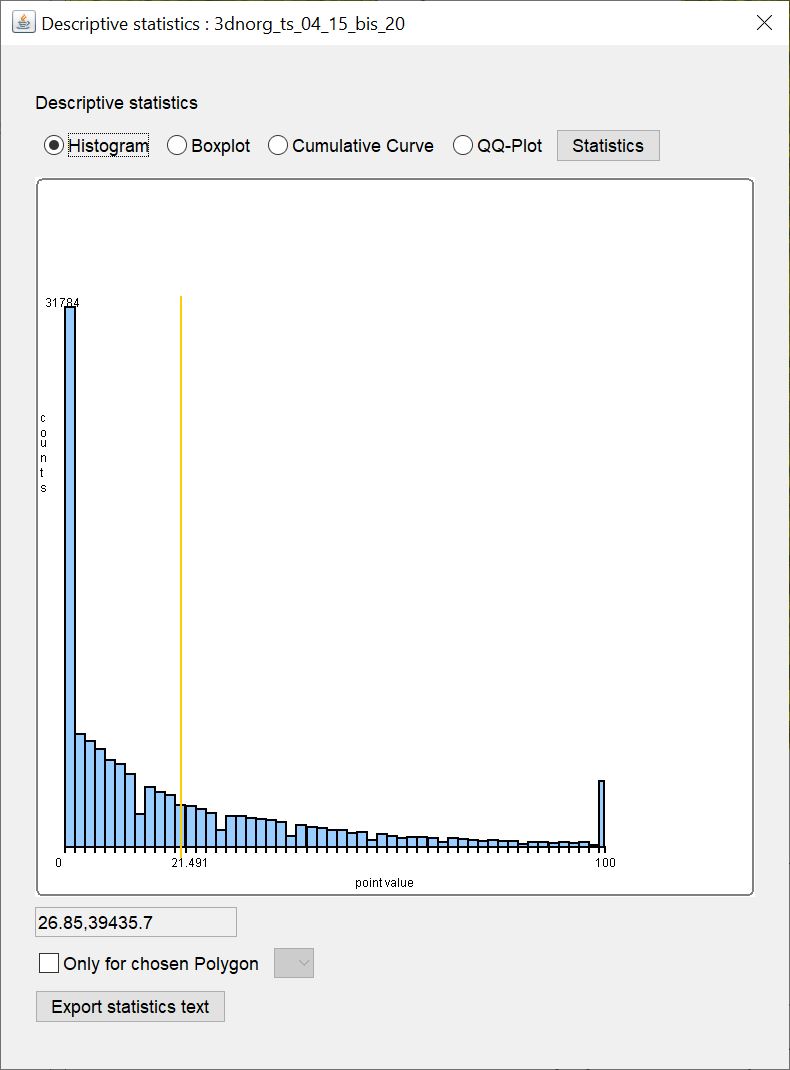
Unter Histogram sehen Sie ein Balkendiagramm über die klassifizierten Wertebereiche mit der Klasseneinteilung der Werte auf der x-Achse und der Anzahl von Werten in einer Klasse auf der y-Achse. Es kann auch großzügig "Histogramm" genannt werden, weil die Klasseneinteilung an jeder Stelle das gleiche Intervall abdeckt - die Klassenbreite ist also überall gleich. Somit korreliert die Anzahl der Werte in einer Klasse mit der relativen Anzahl und kann auf y abgetragen werden. Die Klasseneinteilung wird vereinfacht nach Scott berechnet.
Der gelbe vertikale Strich markiert das arithmetische Mittel. Beinhalten die Eingabewerte nur ganze Zahlen und umfassen diese nur ein Spektrum von unter 15 verschiedenen Zahlen, wird die Klassenbreite auf 1 gesetzt, weil wir davon ausgehen, dass dies klassifizierte Daten darstellen könnten. Das ist ein konservativer Ansatz und passt vielleicht nicht zum Charakter aller Daten.
¶ Boxplot
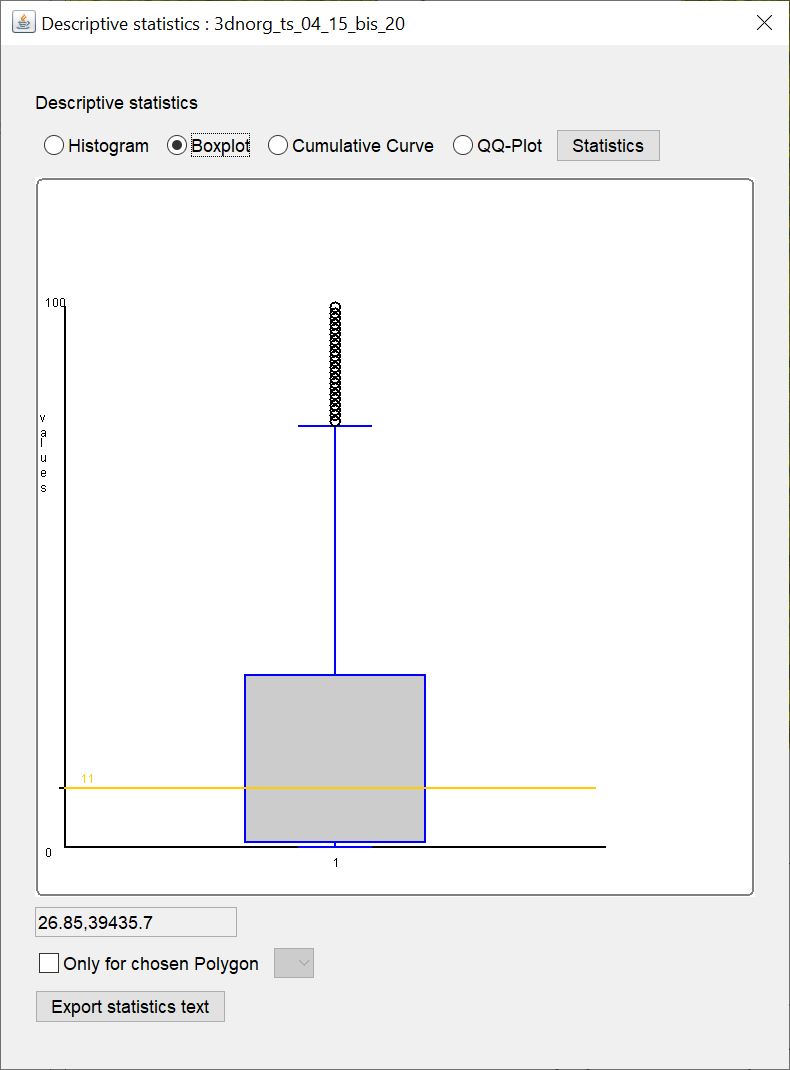
Hier sehen Sie den Boxplot zu den Daten. Der gelbe horizontale Strich markiert den Median-Wert.
¶ Cumulative Curve
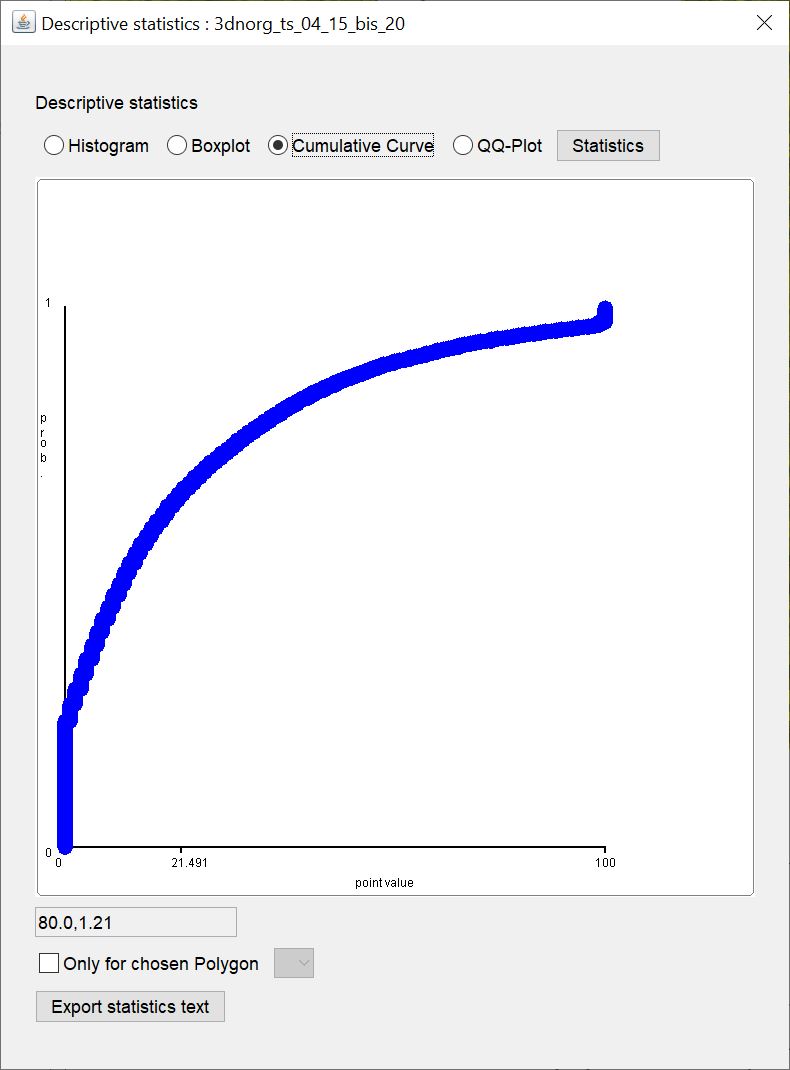
Dieser Plot stellt im eigentlichen Sinne keine Kurve dar. Hier sehen Sie auf der x-Achse den Wertebereich und auf der y-Achse aufgetragen die Quantile (0-1, normed cumulative frequency) eines Wertes. Der Plot zeigt nur die Eingabewerte, aber berechnet keine Kurvenanpassung. Bei der Darstellung sehr vieler Daten, erscheinen die Punkte gemeinsam nur als Kurve.
¶ QQ-Plot
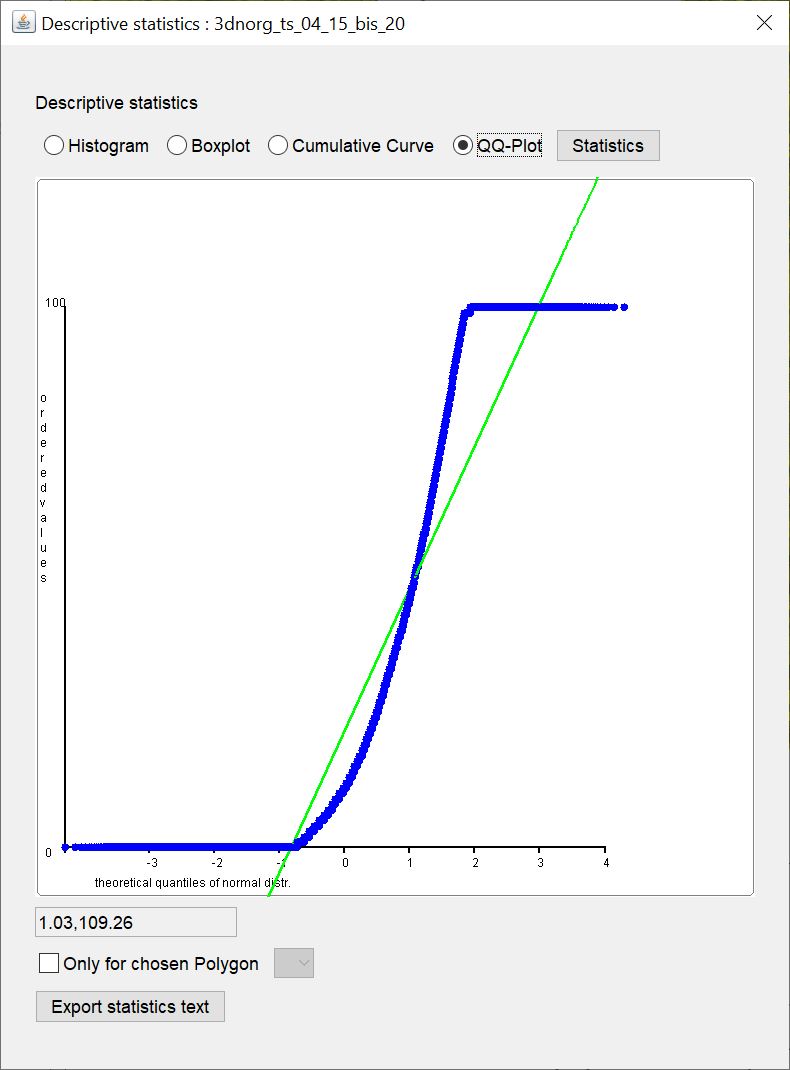
Unter QQ-Plot wird der Quantil-Quantil-Plot angezeigt. Dieser dient vereinfacht zur visuellen Überprüfung, ob die Verteilung Ihrer Eingabewerte einer Normalverteilung nahe kommt. Auf der y-Achse sind die empirischen Quantile gegen die theoretischen Quantile der Standard-Normalverteilung aufgetragen. Die blauen Punkte entsprechen also den Quantil-Paaren zu den Eingabewerten. Der grüne Strich markiert die ideale Linie, wenn die empirischen Quantile tatsächlich exakt mit den theoretischen Quantilen übereinstimmen würden. Je weiter also die blauen Punkte von der grünen Linie abweichen, desto weniger ähnelt eine Verteilung auch der Normalverteilung. Beachten Sie, dass der visuelle Test einen statistischen parametrischen Test auf Normalverteilung nicht ersetzen kann. Jedoch haben wir es in der Geologie (Lockersedimente) häufiger mit Daten zu tun, die nicht normalverteilt sind und deswegen eine Annäherung auch je nach Fragestellungen akzeptiert werden kann, um weitergehende Methoden zu verwenden, wie beispielsweise Kriging.
¶ Deskriptive Statsitik für Text-Daten
Sie können sich zur angewählten Datenreihe (meist erreichbar über das Rechtsklick-Kontextmenü eines irregulären Voxelmodells oder im Parameter Manager) jeweils ein Balkendiagram über die absolute Anzahl der Vorkommen eines Stichwortes, und eines für den prozentualen Anteil an allen Stichworten in der Kategorie.
Unter der Grafik sehen Sie auch ein kleines Textfeld. Es zeigt die Koordinaten Ihrer Mausposition im Grafik-Feld. Es soll Ihnen bei der Auswertung der Graphen helfen.
Mit dem Knopf Export statistics text speichern Sie den Text zur Zählung von Stichworten in einen einfachen Text-File.
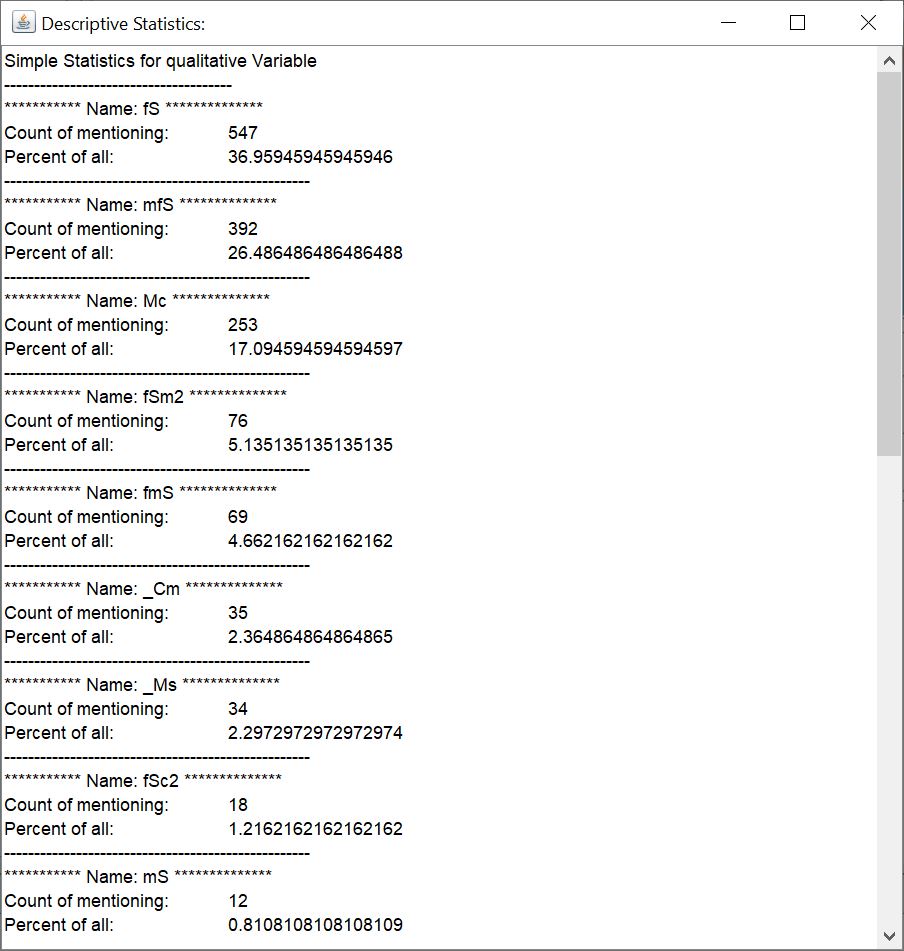 Mit dem Knopf *Statistics* öffnen Sie ein kleines Textfeld mit der statistischen Asuwertung in einen einfachen Text.
Mit dem Knopf *Statistics* öffnen Sie ein kleines Textfeld mit der statistischen Asuwertung in einen einfachen Text.
Übrigens: Wenn Sie Textdatenreihen aus dem Parser für Schichtbeschreibungen oder damit vergleichbare Textformate in die Statistik schicken, findet ein Stringsplitting statt, um die in einer Reihe gelisteten Stichworte einzeln in der Zählung behandeln zu können. Lesen Sie dazu gglfs. den verlinkten Artikel.
¶ Frequency
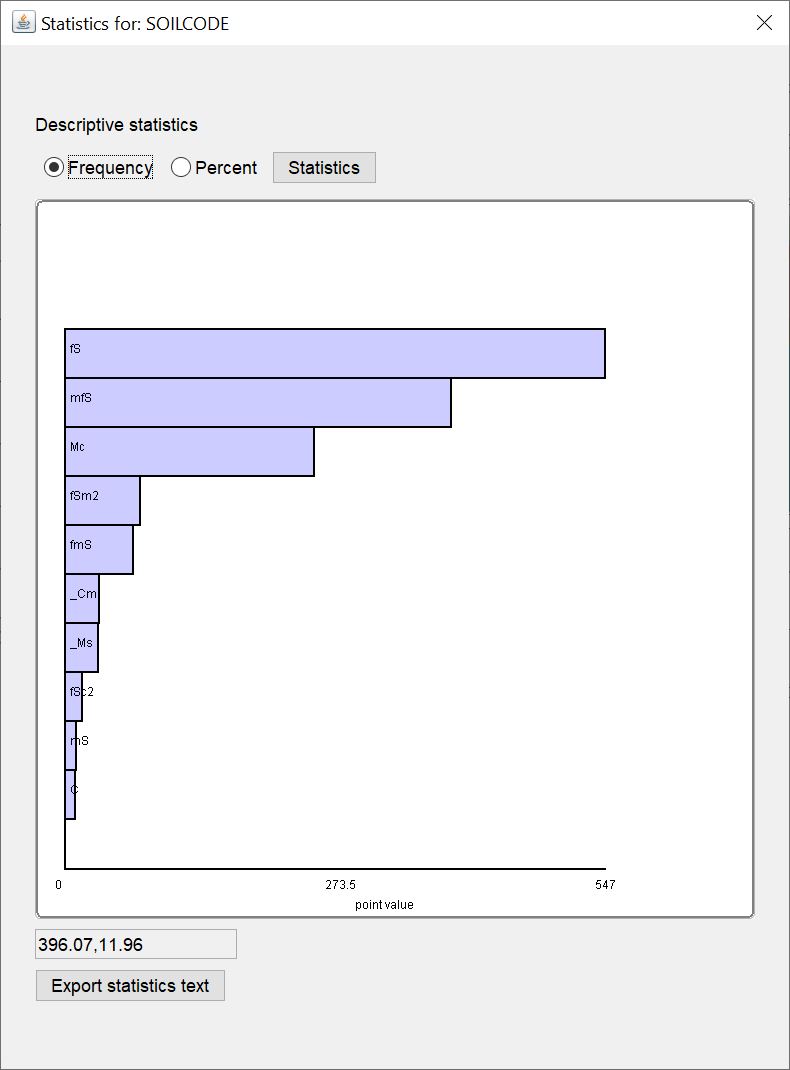
Sie sehen ein horizontales Balkendiagramm mit der absoluten Anzahl von einem bestimmten Stichwort aus einer Text-Datenreihe. Es werden immer nur die ersten 10 Stichwörter mit der höchsten Anzahl gezeigt. Alle anderen können Sie im Text mit dem Knopf Statistics einsehen.
¶ Percent
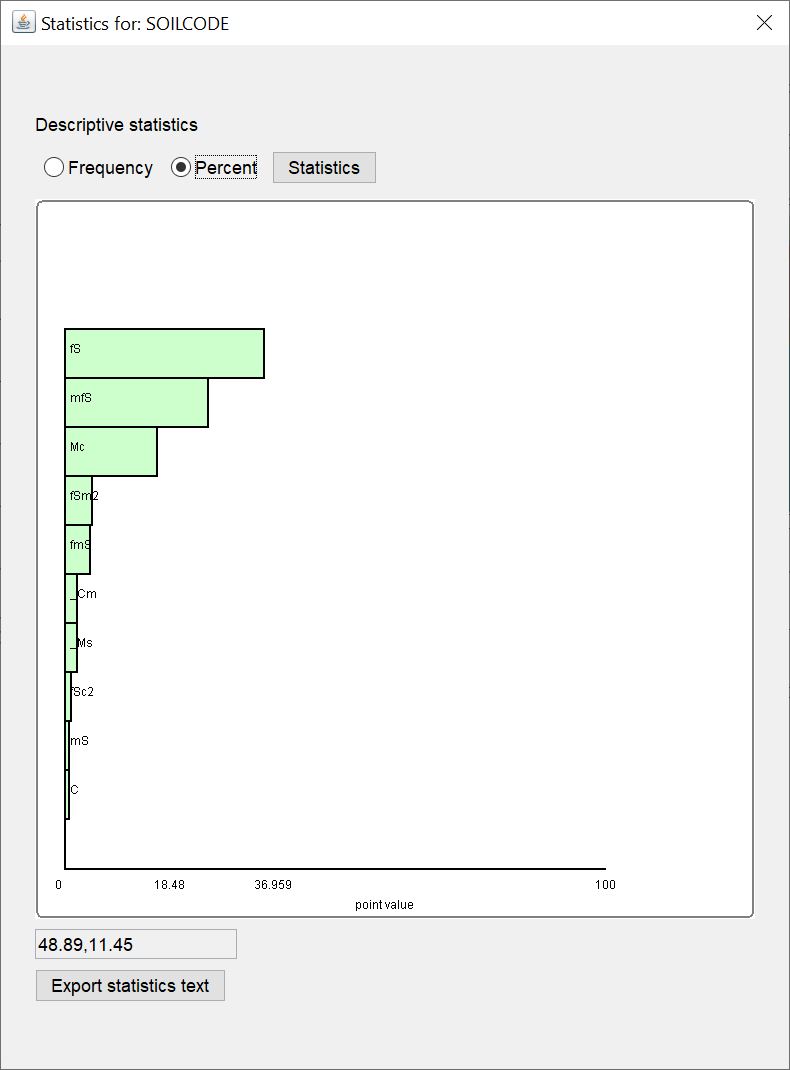
Sie sehen ein horizontales Balkendiagramm mit dem prozentualen Anteil des Vorkommens eines bestimmten Stichwortes aus einer Text-Datenreihe. Es werden immer nur die ersten 10 Stichwörter mit dem höchsten prozentualen Anteil gezeigt. Alle anderen können Sie im Text mit dem Knopf Statistics einsehen.