Hier erfahren Sie etwas über die Möglichkeiten im SubsurfaceViewer auf verschiedenste Weise Klassifikationen durchzuführen.
¶ Lithologische Klassifizierung
Sie können im SubsurfaceViewer lithologische Daten über Funktionen des Parameter Manager klassifizieren.
Die lithologischen Daten sollten entweder in Form von Siebkornanalysen vorliegen oder in als ähnliche Äquivalenten aus Schichtbeschreibungen abgeleitet worden sein. Hierzu können Sie vielleicht auch unseren Parser für Schichtbeschreibungen nutzen. Den Parser möchten wir weiter entwickeln, also kontaktieren Sie uns gerne, wenn Sie daran Interesse haben.
¶ Manuell
Sie können im Soil type module des Parameter Managers Ihre lithologischen Daten manuell klassifizieren.
Folgen Sie hierzu zunächst den Anweisungen in dem verlinkten Artikel zum Soil type module.
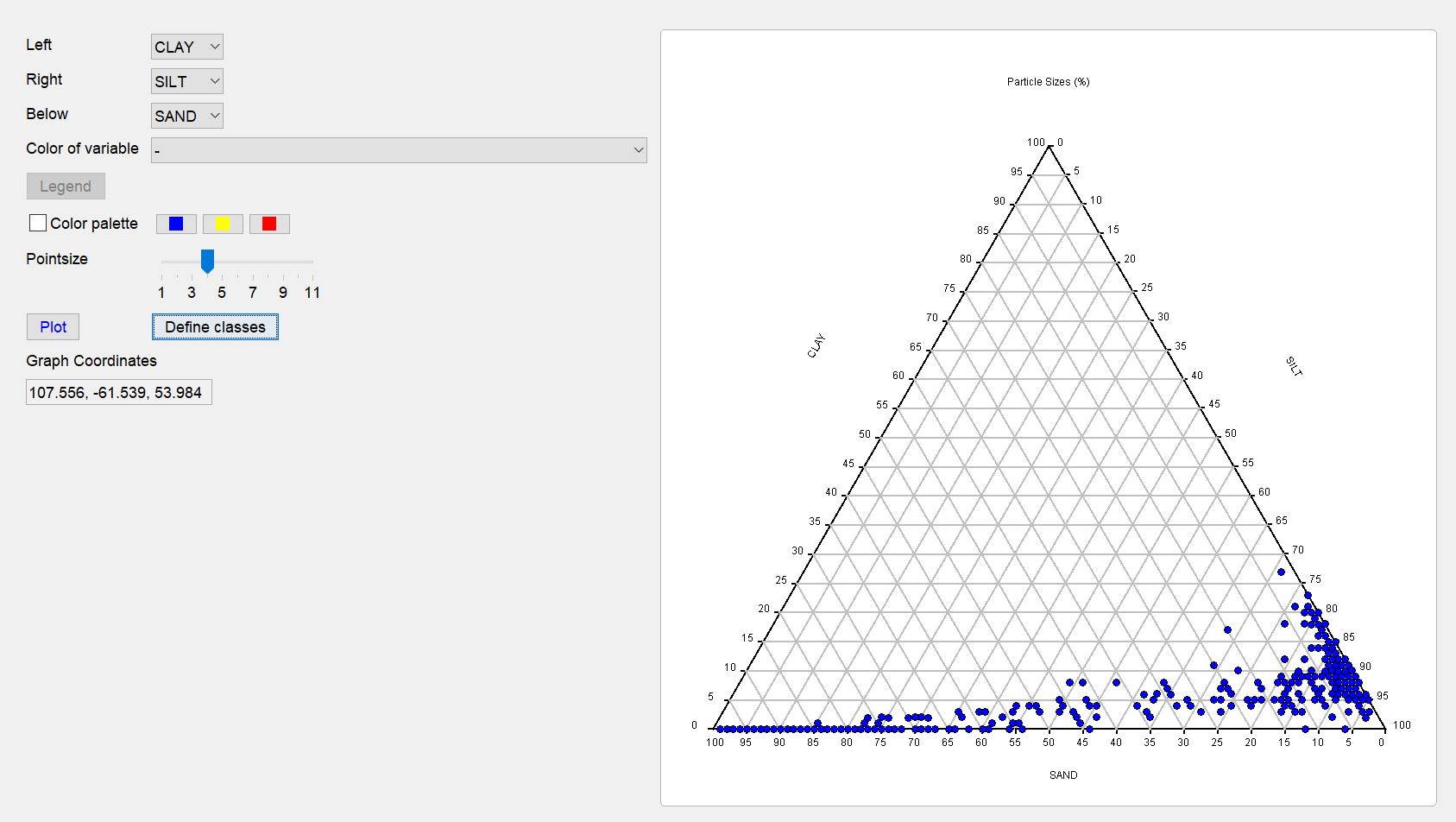
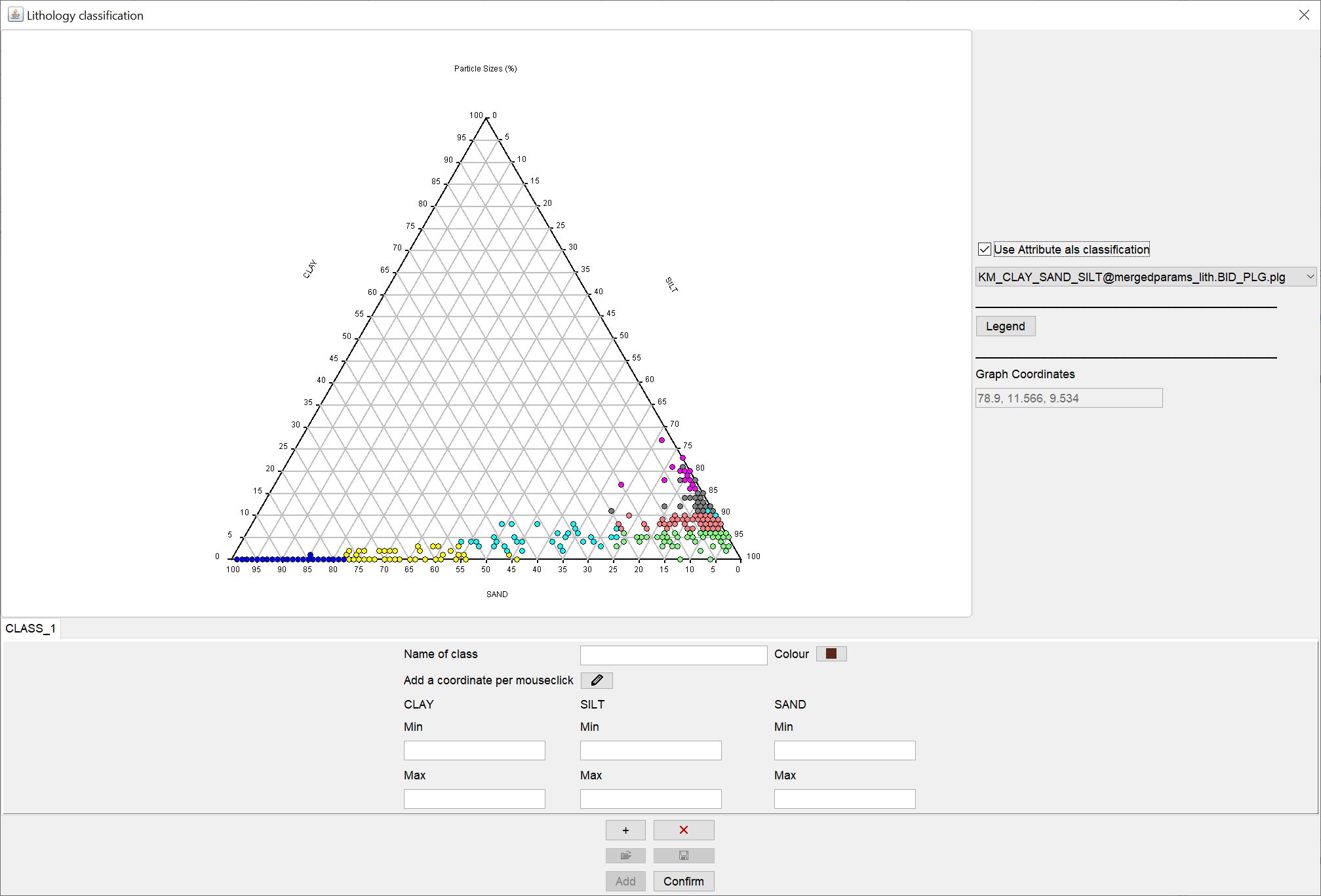
Sobald Sie ein erstes Ternärdiagramm über die Korngrößenverteilungen im Sediment erstellt haben, können Sie mit der Klassifizierung beginnen. Öffnen Sie dazu das Fenster mit dem Ternärdiagramm über den Knopf Define classes.
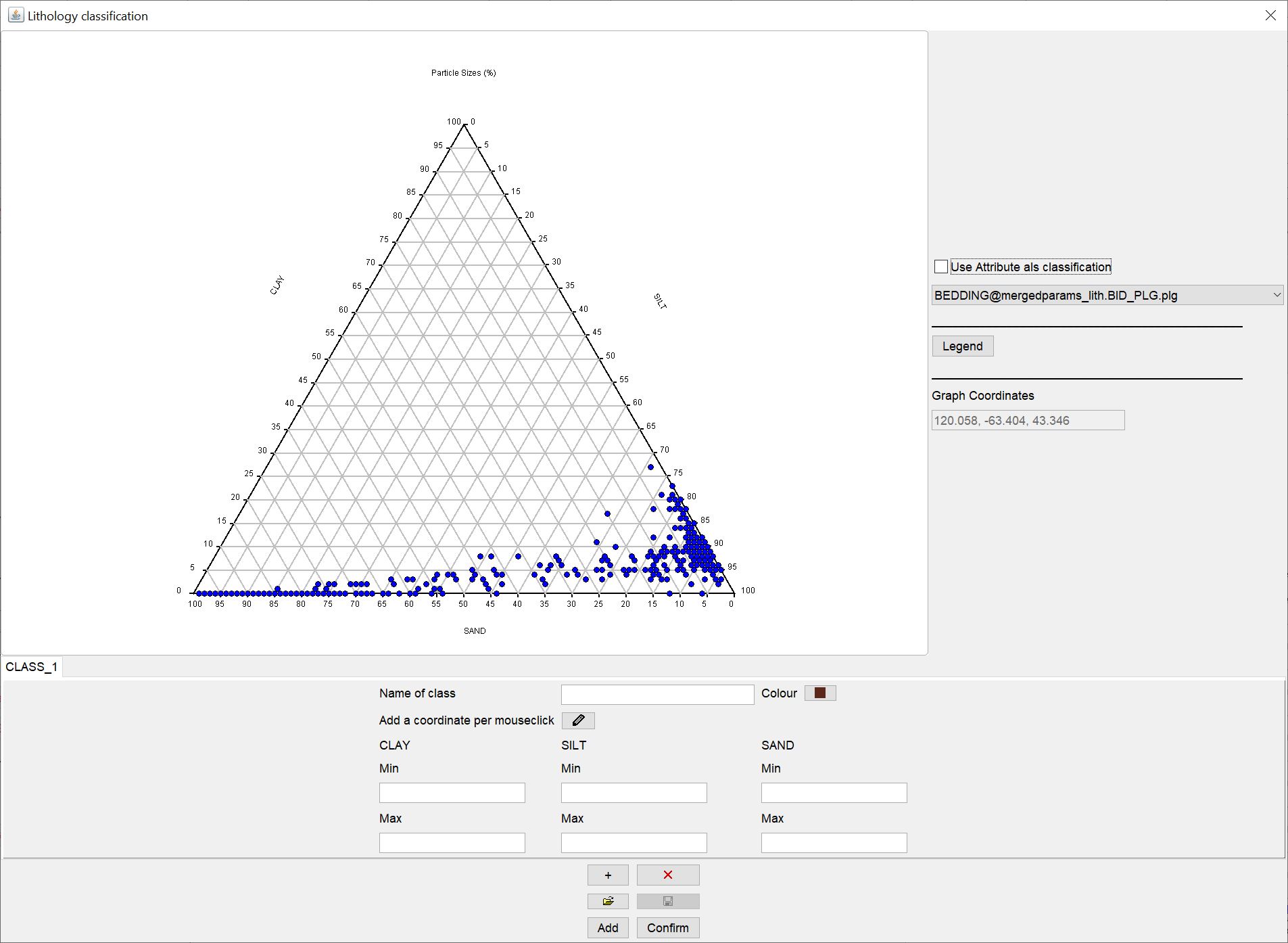
In dem neuen Fenster sehen Sie zentral wieder das Ternärdiagramm über die von Ihnen ausgewählten Korngrößen und mit den entsprechenden Achseneinstellungen.
Auf der rechten Seite können Sie auf Bedarf auch vereinfacht ein Attribut aus der Dropdown-Liste wählen, um die lithologischen Klassifizierung festzulegen. Die Attribute müssten jedoch an denselben Koordinaten der lithologischen Samples sitzen, um richtig zugewiesen zu werden. Diese Option ist also die einfachste und am wenigsten interessante Art der Klassifizierung, kann aber für eine leichtere Nutzung des HCE-Moduls herhalten.
Weiter unten sehen Sie dann ein größeres Optionen-Feld mit dem Sie manuell lithologische Klassen definieren können.
Sie geben unter Name of class einen aussagekräftigen Namen für die erste Klasse ein. Mit Colour legen Sie die Farbe der Klasse fest. In den Textfeldern darunter können Sie, je nach Einstellung Ihrer Achsen im Ternärdiagramm, die Min-Max-Grenzen für den prozentualen Gehalt einer Korngröße im Sediment für diese Klasse direkt eingeben. Wenn Sie lieber die interaktive Variante mögen, können Sie auch den Button mit dem Symbol  drücken. Sie umreißen einfach mit gedrückter Maustaste im Ternärdiagramm das Feld, welches zu der Zielklasse passt. Sie können aber auch einfach die Eckpunkte klicken. In den Textfeldern können Sie die Werte dann auch nochmal nachträglich auf Ihre Bedürfnisse anpassen. Wenn Sie mit dem aktiven -Symbol in das Ternärdiagramm doppelklicken, löschen Sie alle Werte für die Klasse und können von vorne beginnen. Bei inaktivem -Symbol bewirkt ein Doppelklick, dass sich ein Popup-Fenster öffnet, welches Sie zum Speichern des Ternärdigramms in eine SVG-Bilddatei einlädt.
drücken. Sie umreißen einfach mit gedrückter Maustaste im Ternärdiagramm das Feld, welches zu der Zielklasse passt. Sie können aber auch einfach die Eckpunkte klicken. In den Textfeldern können Sie die Werte dann auch nochmal nachträglich auf Ihre Bedürfnisse anpassen. Wenn Sie mit dem aktiven -Symbol in das Ternärdiagramm doppelklicken, löschen Sie alle Werte für die Klasse und können von vorne beginnen. Bei inaktivem -Symbol bewirkt ein Doppelklick, dass sich ein Popup-Fenster öffnet, welches Sie zum Speichern des Ternärdigramms in eine SVG-Bilddatei einlädt.
Wenn Sie ein Zwischenergebnis Ihrer Klassifikation sehen wollen, drücken Sie einfach immer Confirm. Falls Sie Add drücken, wird diese Klassifikation einer bereits bestehenden hinzugefügt. Das ist dann sinnvoll, wenn Sie die Achsen Ihres Ternärdiagramms ändern, dieses Fenster erneut öffnen und weitere Klassen hinzufügen möchten, die andere Korngrößenanteile umfassen.
Zum Hinzufügen einer weiteren Klasse, verwenden Sie unten den Knopf mit einem +-Symbol. Der Knopf mit dem roten X daneben, löscht die gerade im Vordergrund stehende Klasse. Wird eine Klasse hinzugefügt, erscheint sogleich ein neuer Reiter, in dem Sie genauso vorgehen wie bei der ersten Klasse. Sie können soviele Klassen definieren, wie Sie wünschen. Es ist kinderleicht. Probieren Sie es einfach aus.
Das  -Symbol ist solange inaktiv, bis Sie den Knopf Confirm gedrückt haben. Erst dann befinden sich die Klassen tatsächlich im System und können abgespeichert werden. Sie werden in eine für dieses Tool entwickelte *.LITHXML-Datei geschrieben. Diese können Sie auch mit
-Symbol ist solange inaktiv, bis Sie den Knopf Confirm gedrückt haben. Erst dann befinden sich die Klassen tatsächlich im System und können abgespeichert werden. Sie werden in eine für dieses Tool entwickelte *.LITHXML-Datei geschrieben. Diese können Sie auch mit  wieder laden, so dass Sie eine aufwendige lithologische Klassifikation vielleicht nur einmal manuell vornehmen müssen.
wieder laden, so dass Sie eine aufwendige lithologische Klassifikation vielleicht nur einmal manuell vornehmen müssen.
Übrigens: Wenn Sie die Add-Option in mehreren unterschiedlichen Ternärdiagrammen mit jeweils anderen Achseneinstellungen für die Korngrößen verwendet haben, dann werden in die gespeicherte LITHXML-Datei auch alle eingegebenen Klassen enthalten sein. Wenn Sie diese Datei dann laden, werden jedoch natürlich nur die Klassen sichtbar (nach Confirm), die zu den Achsen des gerade sichtbaren Ternärdiagramms passen.
Hier sehen Sie ein Beispiel einer vollständigen lithologischen Klassifizierung.
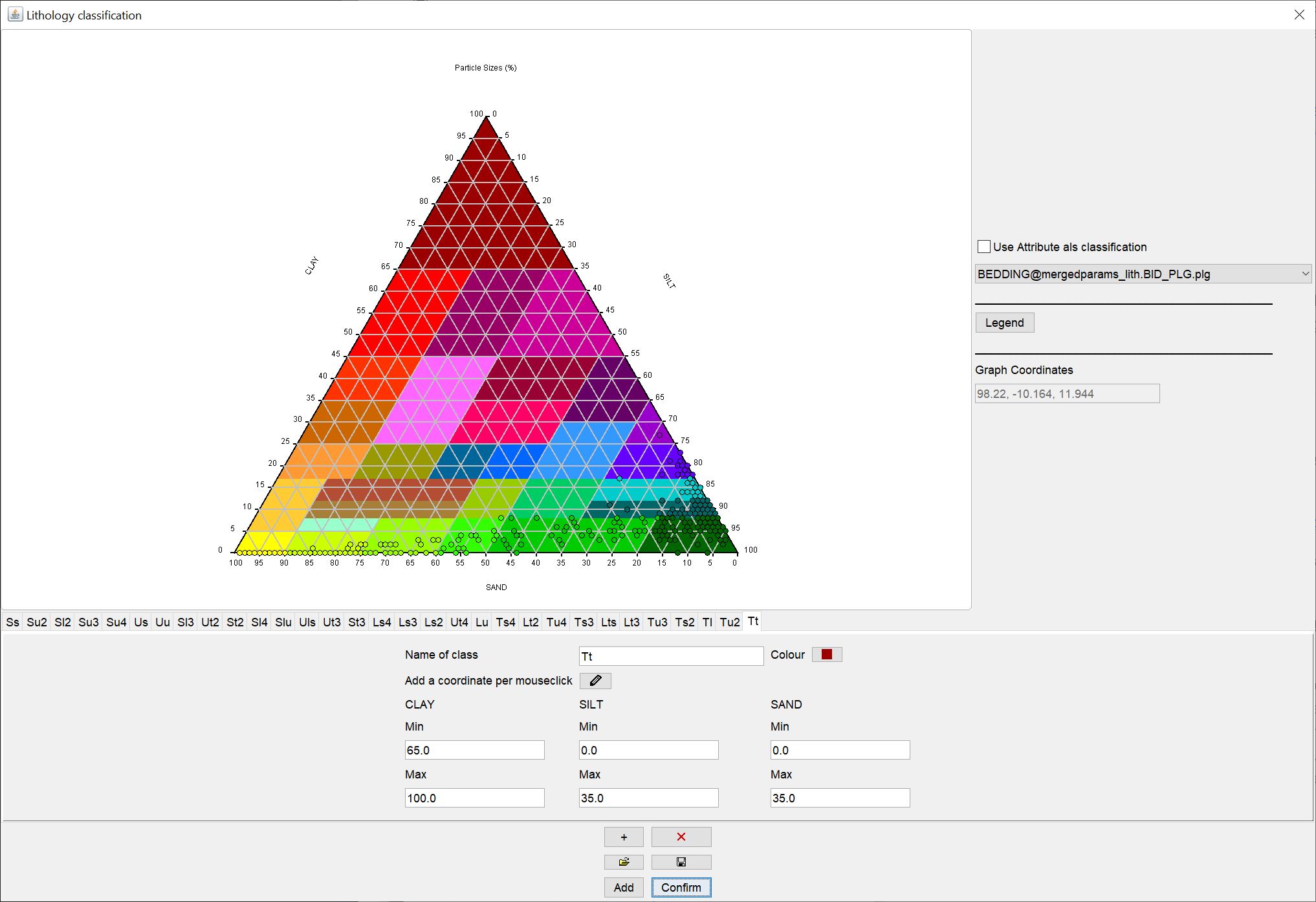
¶ Automatisch
Wir haben einige Erfahrungen mit automatischen Clustering-Verfahren für lithologische Daten sammeln können. Sie könnten also unter Umständen auch unsere implementierte Python-Schnittstelle zum Clustering ausprobieren.
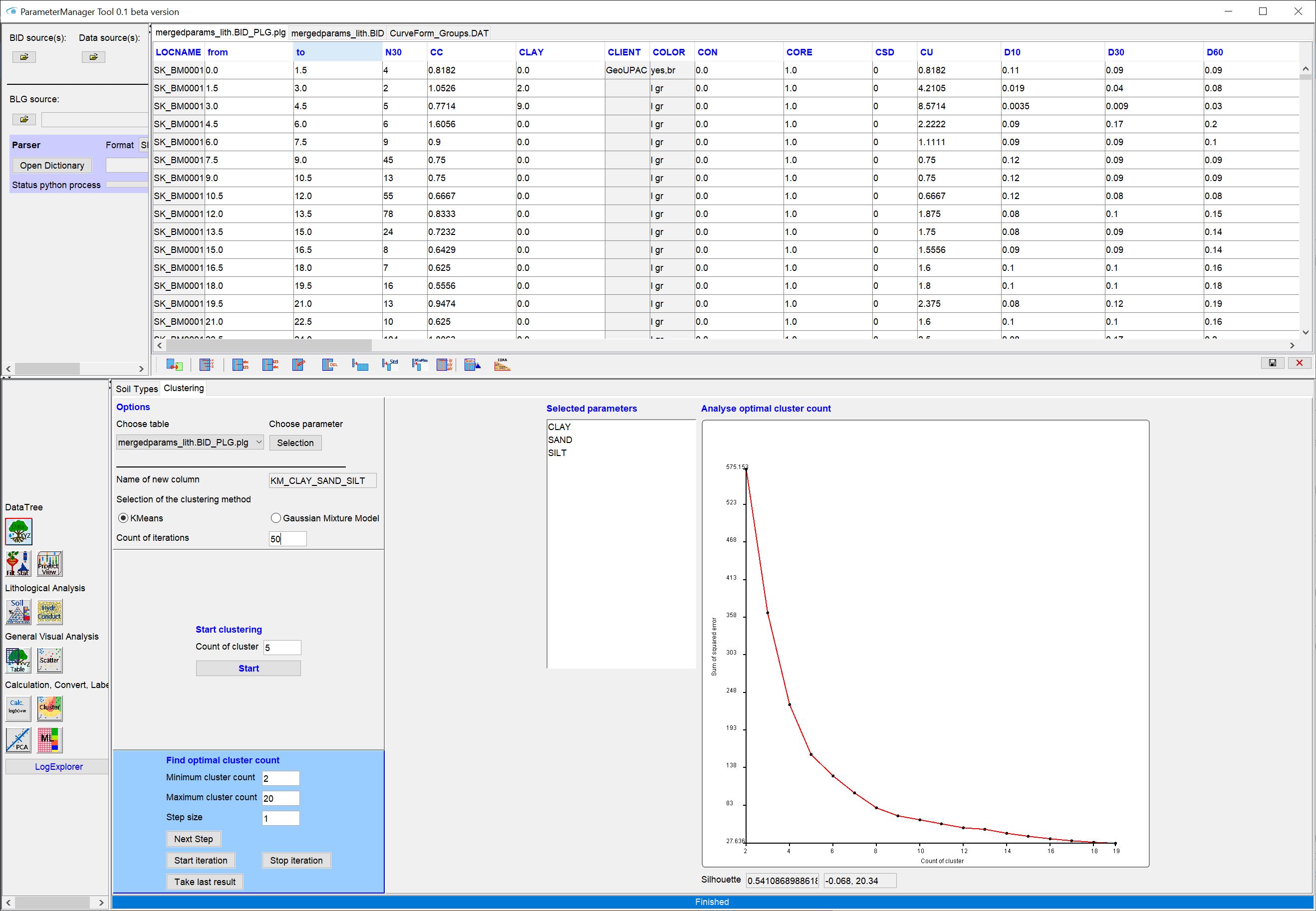
Das ist inbesondere dann sinnvoll, wenn Sie sich noch über die Vor- und Nachteile von bestimmten lithologischen Klassifizierungen im Gebiet unschlüssig sind.
In dem Beispiel haben wir K-means-Clustering verwendet, welches nach unserer Erfahrung sehr robust arbeitet, da es im Wesentlichen auf Distanzen der Wertepunkte zueinander basiert. Diffiziler ist eine Verwendung des Gaussian Mixture Models. Hier müssen Sie ggfls. vorher Log-ratio-Transformationen auf Ihren Korngrößenprozenten durchführen. Das können Sie auch über die Werkzeugleiste für Tabellen im Parameter Manager machen.
Teilen Sie mit uns Ihre Erfahrungen, wenn Sie möchten. Wir sind gespannt, welche Methoden Ihnen in der Praxis am zuträglichsten sind. Schreiben Sie uns einfach eine Email oder rufen uns an.
¶ Klassifizierung von Parametern
Nutzen Sie unsere implementierte Python-Schnittstelle zum Clustering, um bestimmte Parameter automatisch zu klassifizieren.
Für Klassifizierungen, die einen räumlichen Bezug beinhalten sollen, können Sie eventuell eine Kombination aus Filtern und Editieren einer neuen Tabelle gehen. Wir haben das noch nicht ausprobiert. Schauen Sie sich aber mal die Artikel unter Parameter Manager, LogExplorer und LocView-Objekt an. Vielleicht finden Sie dadurch einen kreativen Weg.
¶ Klassifizierung von Raster- und Voxeldaten
Raster und Voxeldaten können sehr einfach über eine Kombination des Filters und des Rechners für Raster bzw. des Rechners für Voxelmodelle manuell klassifiziert werden.
Übrigens: Geofaktoren bringen mit ihren Settings bereits Möglichkeiten zur Klassifikation mit. Lesen Sie sich einfach die Beschreibungen zur Bewertung eines Geofaktors durch. Dort finden Sie sicher eine kreative Lösung.
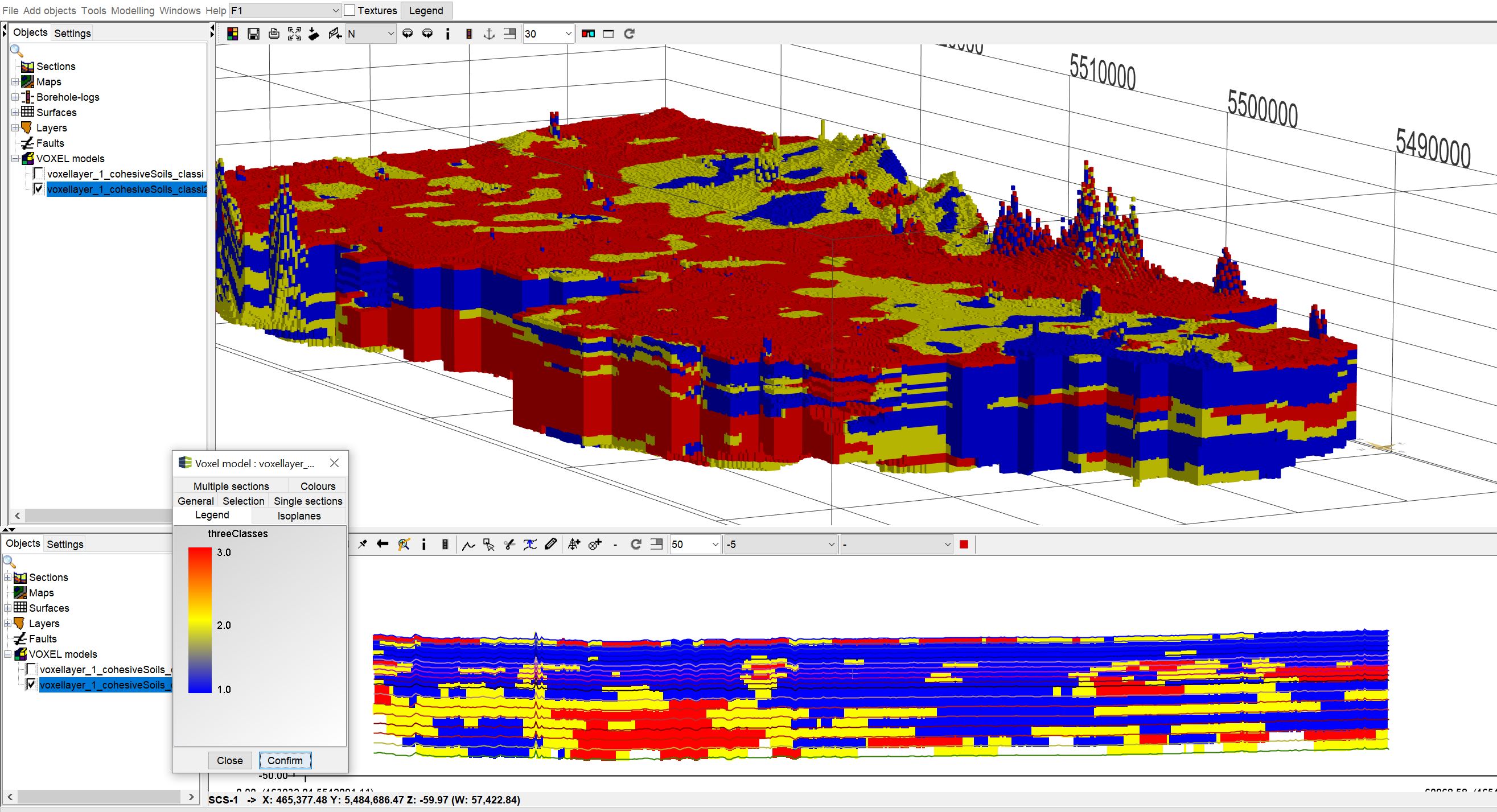
Da die manuelle Klassifikation von Raster- und Voxeldaten exakt gleich abläuft, zeigen wir Ihnen folgend den Ablauf für ein Voxelmodell. Im Beispiel haben wir das Voxelmodell aus dem 3D-NORG-Projekt vom Hessischen Landesamt für Natur, Umwelt und Geologie (HLNUG) verwendet.
Wir haben in der Spalte "Prob_cohesiveSoils" einen Wertebereich zwischen 0 und 100. 0 bedeutet, dass bindige Sedimente mit keiner Wahrscheinlichkeit vorhanden sind. 100 zeigt eine 100-prozentige Wahrscheinlichkeit des Auftretens bindiger Sedimente an. Wir möchten nun eine Klassifizierung der Auftrittswahscheinlichkeiten in drei Klassen vornehmen:
- 0 - 35 %, sehr geringe Wahrscheinlichkeit für das Vorhandensein bindiger Sedimente,
- 35 - 65%, ein Vorhandensein bindiger Sedimente ist möglich, aber nicht sicher,
- 65 - 100% (101 wegen der float-Zahlen-Präzision), ein Vorhandensein bindiger Sedimente ist sehr wahrscheinlich.
- Wir öffnen über die Settings des Voxelmodells den Filter und selektieren schonmal nur diejenigen Voxel, die den Wertebereich der 1. Klasse umfassen.
- Dann öffnen wir den Rechner für Voxelmodelle. Hier setzen wir im kleinen Textfeld oben einen aussagekräftigen Namen für unsere Klassifizierung ein. Wir lassen das Häkchen bei Calculation only on selected unbedingt aktiv.
- Wir geben in das Formelfenster einfach die Zahl 1 ein und bestätigen mit Confirm. Das Fenster des Rechners muss offen stehen bleiben und der Name der Klassifikation darf nicht mehr geändert werden!
- Nun wählen wir in den Settings des Voxelmodells mit dem Filter nur die Voxel aus, die den Wertebereich der zweiten Klasse beinhalten. Im Rechnerfenster geben wir eine 2 ein und bestätigen.
- Dasselbe wiederholen wir jetzt noch genauso für die 3. Klasse.
- Wir speichern das Voxelmodell ab und hängen bei Bedarf die neue Spalte der Klassifizierung an. Jetzt können wir den Rechner auch wieder schließen.
Unten sehen Sie das Ergebnis:
Hinweis: Der Rechner verwendet das temporäre Verzeichnis, um die Zwischenergebnisse abzulegen. Diese dürfen im Berechnungszeitraum nicht gelöscht werden. Außerdem sollte im temporären Verzeichnis genügend Speicherplatz vorhanden sein. Bei großen Voxelmodellen kann das relevant sein. Sie können das temporäre Verzeichnis auch individuell über die Programmeinstellungen auswählen.
¶ Schichtlabeling
Unter Schichtlabeling verstehen wir das Setzen von Labeln an räumlich gesetzten Parametern oder Schichtbeschreibungen. Das Label bezeichnet dabei eine geologische Schicht, wie etwa eine lithostratigraphische Einheit. Hierzu können im SubsurfaceViewer je nach Bearbeitungsstand unterschiedliche Wege gegangen werden.
¶ Klassischer Weg
Hierzu können Sie die Profilschnitt-Konstruktionen nutzen, um Schichten an Bohrungen miteinander plausibel zu korrelieren.
Wenn Sie bereits ein geologisches Schichtenmodell auf diese Weise erstellt haben, können Sie die Dateien, die Sie im klassischen Stil über die Bohrungen eingeladen haben, auch in den Parameter Manager laden.
Dann exportieren Sie an allen XY-Positionen der *.bid synthethische Logs aus dem Schichtenmodell mit der Funktion Export layers at BID positions.
Die Tabelle laden Sie im Parameter Manager zu den anderen Tabellen hinzu. Dann nutzen Sie Table extraction, und wählen ein Attribut aus der *.blg-Datei, welches sicher überall eingetragen ist, beispielsweise Petrographie, als Primärparameter aus.

Die extrahierte Tabelle zeigt die Schichtdaten der Bohrungen mit den Label des erstellten geologischen Schichtenmodells.
Sie können diese Tabelle auch in den Parameter Manager laden und dort die Tools zur Auswertung von Tabellen-Inhalten nutzen, z.B. das paarweise Vorkommen bestimmter Begrifflichkeiten. Sie haben also damit die Möglichkeit Ihr Modell anhand der Bohrungsinformationen auf Plausbilität zu prüfen und ggfls. zu verifizieren. Das ist vor allem dann relevant, wenn Sie sehr viele Bohrungen (>1000) in Ihrem konzeptionell erstellten Modell als Basisinformation vorliegen haben und Sie aufgrunddessen nicht alle in Ihre Profilschnitte einbinden konnten.
Falls Sie keine Tabelle extrahieren möchten, jedoch das Schichtlabeling gemeinsam mit Downhole-Kurven (beispielsweise LITH_COARSENESS (die lithologische Grobheitskurve)) im LogExplorer anschauen und gglfs. mit den Unit-Funktionen dort anpassen möchten, dann müssen Sie nur die Tabelle, die Sie mit der Funktion Export layers at BID positions exportiert haben in den Parameter Manager laden und den Datenbaum aktualisieren. Dann verfolgen Sie die Anleitungen, die Sie im verlinkten Artikel zum LogExplorer finden.
Alternativ können Sie auch die Inhalte eines regulären Voxelmodells mit Schicht-IDs auf die gleiche Weise zum Labeln verwenden. Sie nutzen dafür dann die Funktion Extraction at XY from voxel model.
¶ Experimenteller erweiterter klassischer Weg
Folgen Sie dem Klassischen Weg und erstellen eine extrahierte Tabelle mit den Schichtlabel an Ihren Bohrungsinformationen.
Nutzen Sie diese Tabelle mit unseren eingebauten Shallow Machine Learner-Funktionen im Parameter Manager. Nutzen Sie das Schichtlabel als Trainingslabel. Wenn Sie Bohrungen zu Verfügung haben, die noch nicht gelabelt wurden, fügen Sie sie ggfls. zu dieser Tabelle hinzu.
Die Python-Tools, die wir eingebunden haben, können bei genügend Merkmalen Faustregeln zum Schichtlabeling aus Ihrer konzeptionellen Idee ableiten und sichtbar machen. Wenn diese Faustregeln nicht wieder erkannt werden können, unplausibel erscheinen, oder aber das geschätzte Labeling sigknifikant anders als das des Modells ist, dann kann man den Ursachen dazu auf den Grund gehen. Nicht immer ist die Maschine "schuld". Es kann auch sein, dass die Datengrundlage Ihres konzeptionellen Modells sehr flexible Interpretationen zulässt und diese vielleicht nicht in sich konsistent verfolgt wurden. Vielleicht können Sie so auch die unbekannten Faustregeln zur Modellierung Ihres Kollegen herausfinden und besser verstehen.
Bereiten Sie die Attribute, die Sie am meisten zur Korrelation Ihrer Schichten gesichtet haben (z.B. Sedimentfarbe, Lithologie usw.), in Ihrer Tabelle auf, so dass Sie als numerische Merkmale von der Maschine benutzt werden können. Nutzen Sie dazu die Werkzeugleiste für Tabellen.
Starten Sie den Trainingsprozess mit den Schichtlabeln und den gewählten Attributen und wählen zunächst die Einstellung all vs all.
Sie erhalten eine erweiterte Tabelle mit den geschätzten Labeln der Maschine, die aufgrund des Trainings an Ihren Attributen zur besten Lösung führten. Sie können das Ergebnis mit Ihrem Labeling vergleichen und sich die Merkmalsgewichte (Feature Importance) anschauen.
Sind die Ergebnisse plausibel? Wo gibt es stärkere Diskrepanzen? Warum? Laden Sie diese Tabelle doch in den Datenbaum und erstellen LocView-Objekte mit den Labeln und den Schätzungen. Können Sie dies zur rascheren Verifizierung Ihres Modells gebrauchen? Warum ja oder warum nein?
Ist eine Schicht des öfteren nicht richtig geschätzt worden, können Sie das Labeling auch mal mit der Einstellung one vs rest angehen. Folgen Sie dazu den Anweisungen im Abschnitt des Parameter Managers. Auch hier stellen Sie die gleichen Fragen, wie oben, und werten die Ergebnisse aus.
Haben Sie einen Datensatz von Schichtbeschreibungen, die bereits teilweise mit Schichtzuweisungen gelabelt wurden, und Sie stehen am Anfang der Modellierung, dann können Sie natürlich auch das entsprechende Label-Training nutzen, um noch ungelabelte Bohrungen zu labeln. Nutzen Sie auch hier LocView-Objekte zur Visualisierung in Ihren Profilschnitten oder in der 2D-/3D-View. Dies könnte eine gute Hilfestellung für Sie sein, um einen Überblick über die Daten zu erhalten und schonmal erste Merkmale für bestimmte Schichten typisieren zu können.
Wichtig: Der beschriebene Vorgang ist als Vorschlag zu verstehen, um sich erst einmal an die Nützlichkeit von Maschine Learning Methoden ranzutasten. Die Tools und beschriebenen Wege dienen also zunächst nur für den Einstieg und als Unterstützung für Ihre Modellierung im Pre- oder Postprocessing. Sie sollten die Ergebnisse immer sorgfältig sichten und prüfen. Nutzen Sie sie nicht gleich, um Unsicherheiten zu quantifizieren. Dazu wäre mehr nötig! Außerdem sollten Sie auch mal verschiedene Einstellungen und Merkmalskombinationen testen. Falls Sie tiefer in das Thema einsteigen wollen, dann sollten Sie direkt auf den verfügbaren Python-Bibliotheken arbeiten.
Kontaktieren Sie uns gerne, wenn Sie hierzu Austausch suchen.
Beachten Sie auch, dass die Funktionen, die Sie im Parameter Manager vorfinden, z.T. noch in einen beta-Zustand haben, weil uns die Testmöglichkeiten bis jetzt fehlten. Bitte melden Sie sich also auch, wenn Sie etwas vorfinden, das Ihnen wie ein Fehler vorkommt.
¶ Flexibles manuelles Labeling mit dem LogExplorer
Um die Labeling-Funktionen im LogExplorer zu nutzen, müssen Sie die Schichtinformationen, also entsprechende Merkmale, in numerischer Form (Downhole) zur Verfügung haben.
Falls Sie "nur" auf Schichtbeschreibungen zugreifen können, könnten Sie sich mit dem Parser für Schichtbeschreibungen und den lithologischen Kurven befassen. Vielleicht ist das für Sie nützlich. Den Parser möchten wir weiter entwickeln, also kontaktieren Sie uns gerne, wenn Sie daran Interesse haben. Sie können sich Ihre Inhalten der Schichtbeschreibungen natürlich auch anderweitig in numerische Werte übersetzen. Letztlich benötigen wir immer bloß ASCII-Tabellen mit einem passenden Trennzeichen. Lesen Sie ggfls. auch den Artikel zu den Formaten.
In jedem Fall, müssen die entsprechenden Tabellen, die die Daten beinhalten, mit dem Parameter Manager erst einmal eingeladen werden. Folgen Sie den Anweisungen im verlinkten Artikel. Vergessen Sie nicht den Datenbaum zu erstellen. Dann öffnen Sie den LogExplorer und wählen einen oder mehrere Merkmale zur Veranschaulichung durch Downhole-Kurven an. Wenn Sie Kernfotografien besitzen, schauen Sie sich den Artikel zu den Kerntextur Tabellen an. Sie können Sie nämlich als Hintergrundbilder zu Ihren Kurven zuladen. Dann folgen Sie den Beschreibungen, die Sie LogExplorer im Abschnitt Labeling -> Units sehen. Nutzen Sie den Datenbaum und das LocView-Objekt, um die erzeugten Schichtenlabel auch im Profilschnitt oder in der 3D-View zu sehen und auf Plausibilität zu checken.